

Malware authors use a variety of methods to hide their creations from detection and cybersecurity analysts. However, researchers find similar samples by advanced hash algorithms. Today we will tell you how one of these algorithms work and show examples.
Why do we need to identify malware similarities?
In most cases, the existing base or core of malware is reused to create a new type of malicious program. Malware writers don’t bother with the time-consuming design of new and “qualitative” viruses, they usually use already existing samples.
The code is used again to :
- compile it again by another compiler
- delete or add some features to it
- update some libraries
- change the distribution of the code inside of a file (thus, new linkers, packers, obfuscation are applied).
- replace server IP addresses where data will be sent and downloaded.
The goal of these changes is to reshape malware, so it can stay unrecognizable for a while and infect more machines. Nevertheless, there are methods to detect this kind of repackaging and modifications.
These techniques are often used to analyze a big amount of data and find common elements there. Practical use cases of these methods can be found in the Threat Intelligence approach or ANY.RUN’s Public Submission section.
A hash function
In 1940 Hans Peter Luhn from IBM developed systems for data analysis, including data storage, transfer, and search for text information. It resulted in designing transformation algorithms and then hashing data to find phone numbers and text. These were the first steps in computer science.
Now there is a big number of hash algorithms that are distinguished by their collision resistance, calculation speed, bitterness, and other characteristics.
We are used to thinking that hash functions are similar to cryptographic hash functions. This is a common tool that serves for different goals, like:
- Authentication
- Electronic signature
- Malware detection (files, IOCs)
Let’s find out how hash algorithms help to fight against malicious objects and documents.
What is a hash?
A cryptographic hash function, also called a hash, is a mathematical transformation that maps data to a bit string with numbers, letters, and a fixed size.
A hash is collision resilient, if:
- You can’t restore the input data using a hash.
- It’s challenging to get identical hashes from different input data.
MD5, SHA-1, and SHA-256 are the most popular cryptographic hash algorithms to detect and attribute malware samples. Not long ago malicious objects were recognized only by signatures (a hash) of the executed file.
However, in the modern world, it is not enough just to know the hash of the object as it’s quite a weak indicator of compromise (IOC). IOCs are artifacts that are used to detect malware. For example, IOCs can be registry presets, downloaded libraries, IP addresses, used ports, and a URL.
Let’s have a look at David Bianco’s Pyramid of Pain. This cybersecurity analyst described the level of IOCs’ difficulty that hackers use during attacks. In one case, if you know the MD5-hash of a malicious file, it is quite easy to detect it in the system. However, it will cause no pain to attackers. They will add one more bit of data to malware and the hash will change. In this scenario, a virus can be altered endlessly and each copy will have a different hash from others.

If you deal with numerous malicious samples, it becomes clear that most of them are not original at all. Cybercriminals often borrow or buy the source codes from each other and use them in programs of their own. It’s a common practice when malware appears in the wild, and a lot of fake versions made of available fragments come up.
How to identify similarities of different malware samples of one family? There are special algorithms of hash calculation that aim to find these similarities. For example, fuzzy hashing. This technique finds repeated fragments of malware that belong to specific families.
What does fuzzy hashing stand for?
If an algorithm of a cryptographic hash function involves the smallest change of input data, even a bit of information, the hash transforms completely, too. Here we can say that fuzzy hashes are more preferable in regard to minor changes in a file such as c2 server, configuration information and so. And these alterations aim at a small part of the fuzzy hash compared to the cryptographic one. That is why these functions allow detecting new malware modification more effectively and don’t require a large number of resources for calculation.
So-called “Fuzzy hashing” is a set of methods to preserve the similarity of hash functions or similarity digest. It is also a type of compression function for computing the similarity between individual files. Fuzzy hashing uses context-triggered piecewise hashing (CTPH).
The classification of fuzzy hashing is pretty wide.
According to workflow, algorithms can be:
- piecewise hashing,
- context triggered piecewise hashing,
- statistically improbable features,
- block-based rebuilding.
According to the type of processed data, there are the following types:
- Bit
- Syntax
- Semantic
But if we talk about fuzzy hashing, there is one method that is used the most – CTPH.
The SSDeep program was designed by Jesse Kornblum for computer forensics. It is based on the spamsum code. SSDeep computes several traditional cryptographic hashes of a fixed size and specific file fragments. This way the program identifies similar objects.
How does SSDeep work?
The program consists of the following steps:
- It divides a file into smaller parts and analyzes them, not the whole file.
- It can identify file fragments that have similar bit sequences and order. Also, it can work with bits of 2 sequences where they can differ according to length and value.
SSDeep works with different kinds of malicious content including executable files, malicious documents, and others. Today we will focus on malicious documents to better illustrate this approach.
How can we identify malicious files’ similarities with SSDeep?
If you go to ANY.RUN Public Submissions, you can find a huge collection of samples there. We will investigate malicious documents, use the “maldoc-42” tag to find the samples we mention today.
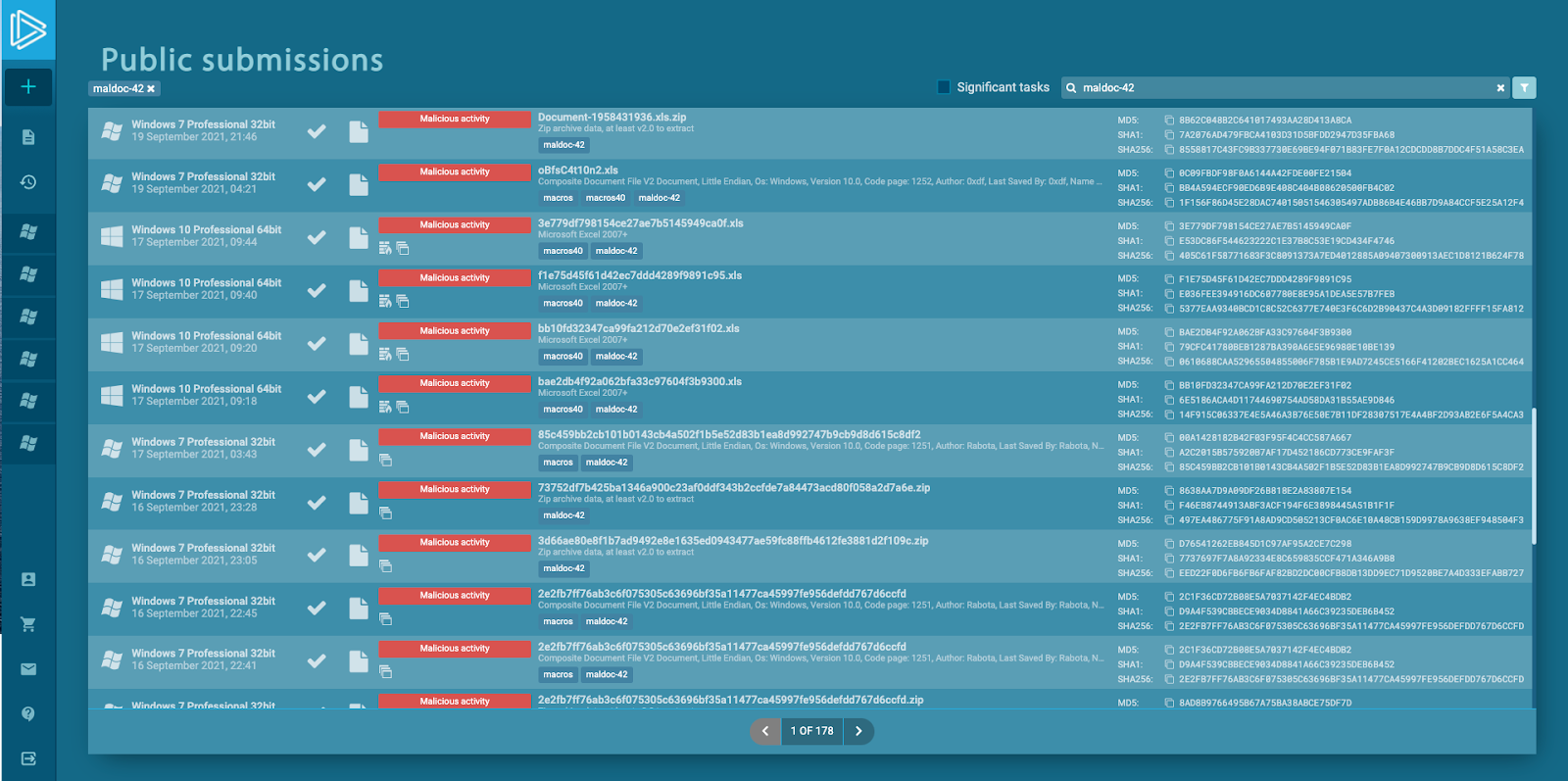
Let’s run one sample. Here is an excel file with quite a distinct picture with DocuSign written there. If we open one more sample, with a different hash we can see the DocuSign template again. Does it mean that these different samples have similarities?
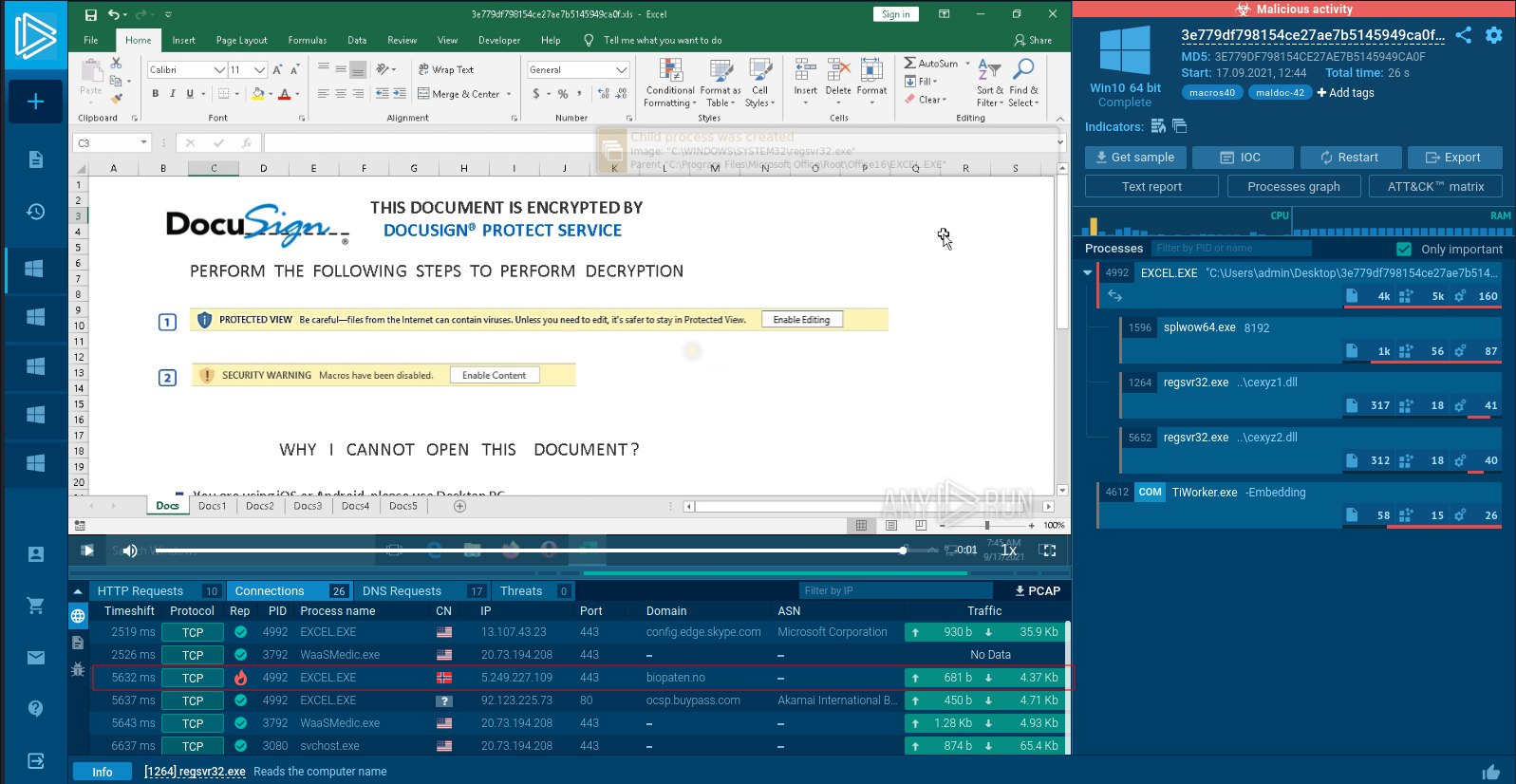

We took 11 samples of maldocs and each analyzed object has a unique cryptographic hash sum MD5.
Using SSDeep we can calculate the piecewise hash of each file and save it.
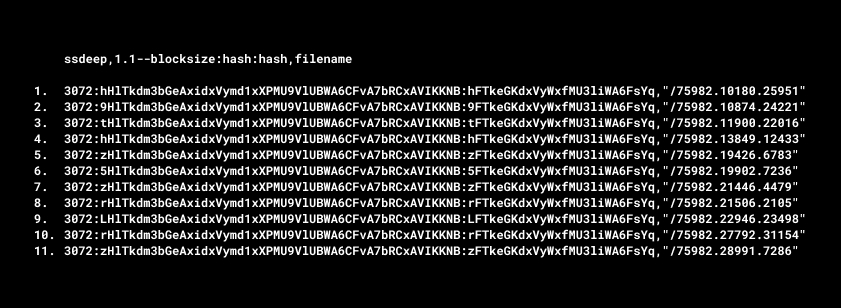
Maldocs files have different and similar hash fragments.
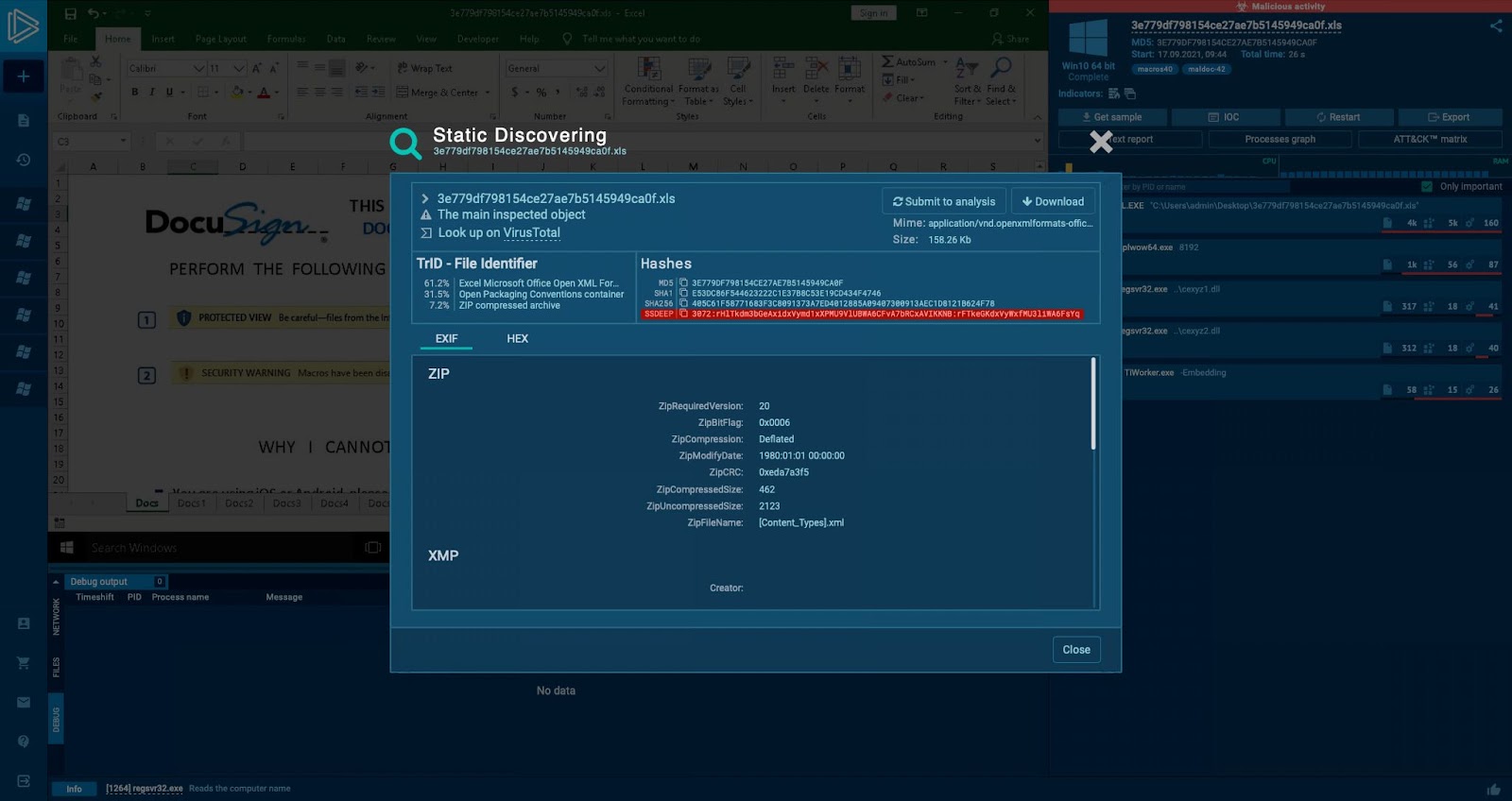
Fuzzy hash can also be found in ANY.RUN’s Static Discovering window by SSDeep name.
Let’s compare all analyzed objects between each other using fuzzy hashes. The percent of matching is on the right.
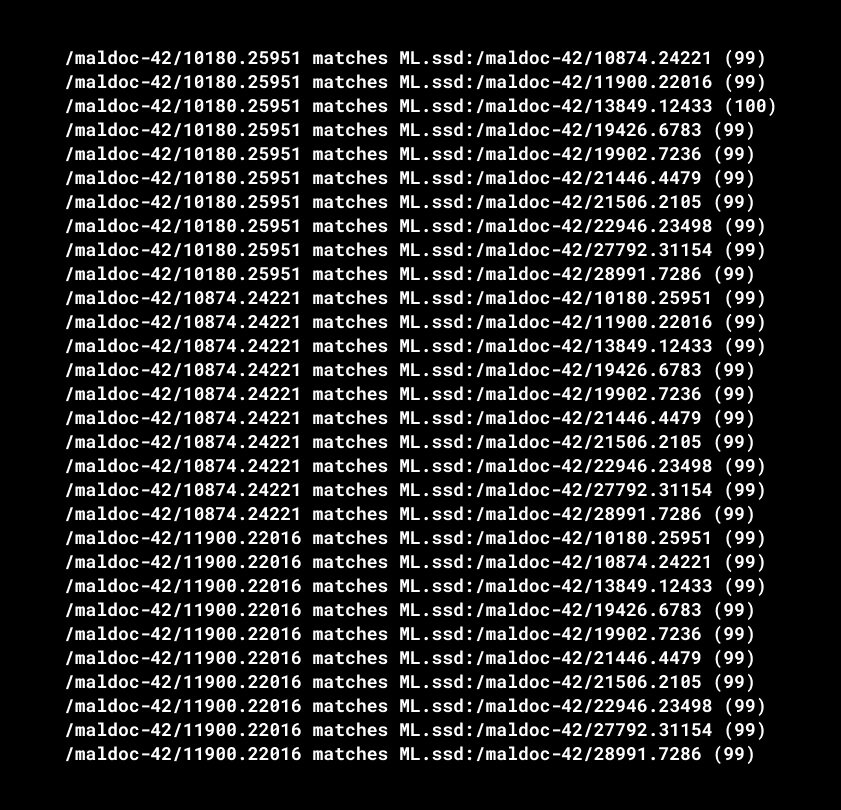
The image above shows 3 samples compared with others. It turns out that these maldocs have parts of code used constantly, that is what provides a similarity. And other maldocs keep the same tendency. And 5 pairs of them are even 100% identical.
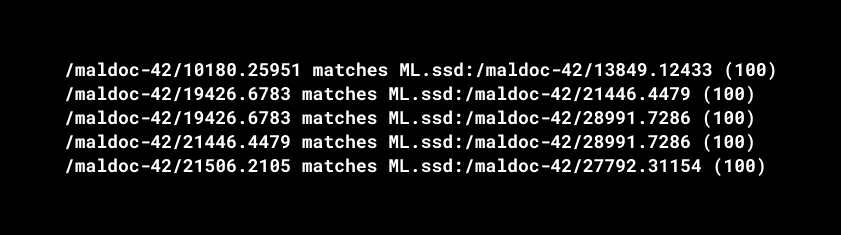
As a result, we have reviewed 11 maldocs with unique hashes. The found SSDeep showed 99% similarity between samples. Why is it so? They contain the same graphical pattern and deliver the same trojan malware.
Despite the fact that all files in our experiment seemed exclusive, the high percentage of their similarity allows automatic detection of other malicious samples faster. Including unknown files for your system. Check the similar tag, see their behavioral details and you can predict what this new sample has inside, without opening it. The lifehack saves time and keeps you safe.
What is the benefit of fuzzy hashing?
While analyzing malicious documents by SSDeep, we have got new relations between objects. Moreover, we have extended the knowledge base about these samples. It helps to effectively complement signature malware analysis with relatively low cost and quite reliable samples’ footprints.
Of course, there are other ways to find connections between different malware like imphash and others. We will try to cover them in the future. Please leave a comment if you like this topic.




0 comments