



Creating a Threat Intelligence Lookup platform is something we have wanted to do for years. With over 400,000 analysts using our sandbox, many of whom run public research sessions and share the results of their research, we’re accumulating roughly 600 million IOCs a year in our database. It was clear to us that information could bring immense value to SOC teams.
Today, we want to raise the curtain a bit and talk about the main milestones (and roadblocks) we hit on the way, as well as the key decisions that shaped the product into what it is today — and where it’ll go next.
Learn more about Threat Intelligence Lookup and what it can do.
We wanted to link all events within a single sandbox session and make them searchable
There were two things we knew: providing a portal to search our database would bring immense value to our users, and we’re the only company that can provide IOCs and events’ filelds extracted from 1.5 million interactive sandbox research sessions, where all events within a single session are linked (even if one event hasn’t directly spawned the other).
There were also many things we didn’t know: how to make the search functionality as intuitive as our sandbox is, and what do we need to do to make sure everything works at scale?
We’ve set goals to ourselves:
1. Supporting wildcards and operators. Wildcards (*) let you quickly find relevant artifacts by substring (querying “vate” returns “privateloader”). Operators enable you to narrow down results using AND, OR, and NOT conditions. (Note: You can already use AND, but we’ll add OR and NOT in a future release).
2. The search had to be fast. We set a condition: users should receive results in seconds, not minutes. (The final render time we achieved is around 5 seconds).
3. The UI had to be intuitive. We needed to design a simple and instantly accessible UI where even a first-time user could build a complex query.
Some things we tried and what didn’t quite work out
Our first instinct was to integrate the Lookup service into the sandbox. We spent months going down this path, but ultimately, we tossed the idea aside.
Our existing MongoDB database holds a large volume of data and the searches took painfully long. Then there was the issue of scalability. With MongoDB being NoSQL database, storing a large number of connections in memory made the infrastructure too expensive to run. That would drive up the price past the point that we were comfortable with.
We also found that using a regular filter on MongoDB and only relying on exact matches meant we couldn’t implement wildcard searches, which was a deal-breaker.
Dmitry Marinov, CTO
Early UX tests reinforced the conviction that cramming the functionality of a search portal into the sandbox wasn’t the right approach.
Initially, we thought to make the lookup part of the sandbox. But we quickly realized that such huge functionality could interfere with standard sandbox use cases. That’s why we decided to create a new service from scratch. This would allow us to develop a search-only interface.
Kirill Aksenov, Head of Design
We decided to make the TI Lookup a separate product
On the backend, this meant a new tech stack and a new database.
We had very high requirements for read and write speeds so that we could build something that’s both quick and easy to use — in the true ANY.RUN fashion.
Dmitry Marinov, CTO
Over the next several months, Dmitry started researching various architectures. Our platform needed to handle hundreds of thousands of events per second and deliver query results for all fields to users in under 10 seconds, worst-case scenario.
Since we needed connections, Dmitry decided to use a graph database. At that time, we were looking at noe4J and OrientDB. The first option Dmitry considered was noe4J. It satisfied all his requirements but was tremendously expensive.
OrientDB, on the other hand, had a free license. And so, Dmitry wrote a connector in NodeJS. It all went smoothly — and we could run searches.
But then we realized that we have so much data coming in from the sandbox that orientDB can’t keep up. We wrote slower than we read.
Dmitry Marinov, CTO
Dmitry moved the OrientDB database to a separate server and rewrote the connector in Java to have it receive data over the network and then write it directly to hardware. This way we could utilize the full speed of the SSD. The write speed increased by 10x, and it was enough to cover our needs. It looked like this was the turning point. And then — we hit a snag:
When I began testing the entire system and tried to scale it, it turned out that when we write to this database over hardware, we cannot read from it. The technology has not justified itself.
Dmitry Marinov, CTO
Then Dmitry tried several things. He tried PostgreSQL, MariaDB, built-in full-text indexes for LIKE queries, custom indexes, and ZomboDB — another dead end.
At one point I started writing custom indexes that allowed us to search through data more efficiently. In particular, I used n-grams. It didn’t pay off again. It turned out that in order for SQL to work, it was necessary to build a 1-gram and the amount that the index occupied was so large that the license price would be too expensive.
Dmitry Marinov, CTO
Just when it started to look like there’s no solution, Dmitry hit a breakthrough:
I took Elasticsearch and structured all our data in a denormalized format within the distributed engine, and that’s when it all clicked. We were able to scale the system for both reading and writing. We have our secret sauce for optimizing everything, and as we scaled it up, it worked!
Dmitry Marinov, CTO
We had to create a completely new UI for searching
In the meantime, breaking away from ANY.RUN’s existing UI kit allowed Kirill and his team to work much more freely. Intuitive workflow is a big part of our sandbox, and we had conviction the UX had to be simple and instantly accessible in the search portal.
We wanted to empower even newcomers to write complex queries with AND conditions and wildcards.
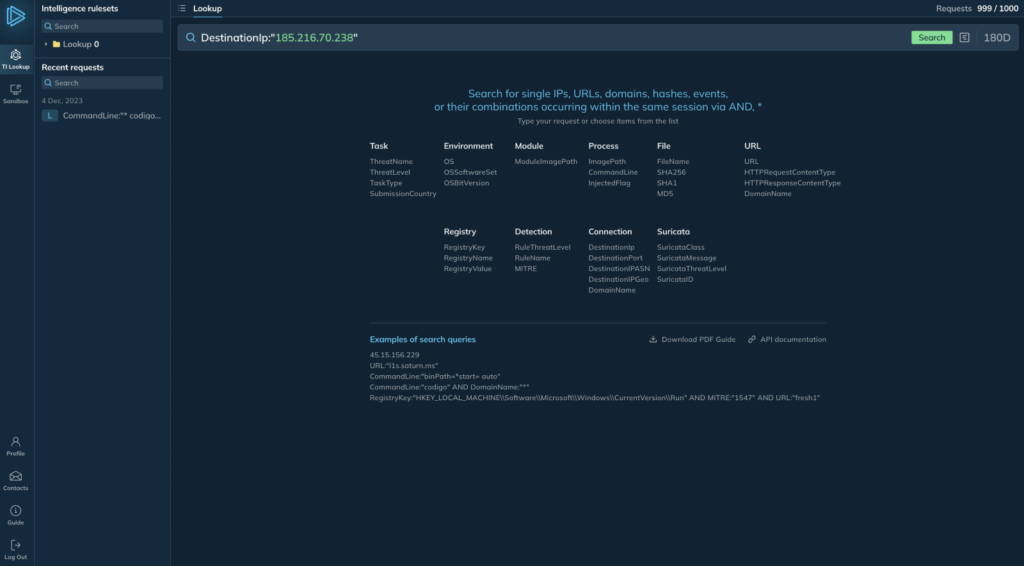
We designed a request constructor that allows you to put together a request by combining pre-built list items. This way we can show users what they can search for and what tools they have to write the request. This was the most challenging part of the UI too get right.
Kirill Aksenov, Head of Design
We made several important decisions about the product during the design process:
Giving a holistic view of search results. Instead of spreading search results across pages by category (you’d have one page to hold IPs, another one for hashes and so on) after much trial-and-error we landed on a tiled layout with a mix of tables and lists. Every search gives you an entire picture at a glance. Then, you can fall into categories by clicking on tiles.
We wanted to retain the connection between Lookup and Sandbox. When we designed the UI, we tried to maintain this connection through interfaces elements; It is reflected in common interface elements like process cards. This is how we create a consistent experience.
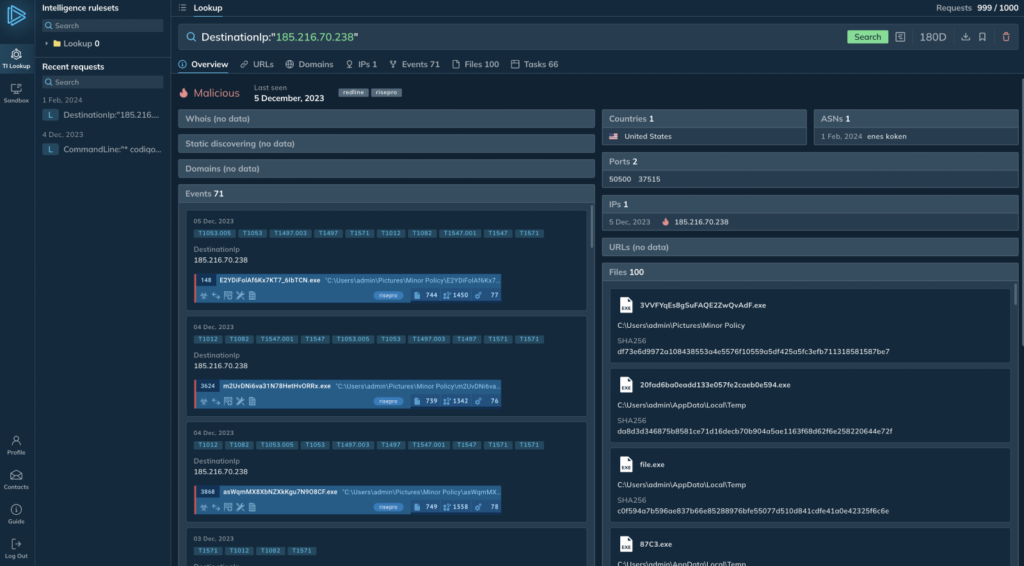
What we want to improve: We included examples of queries, guides and hints in the first iteration of the UI, but we want to make creating a search query for the user even more understandable and transparent.
What’s next for us?
We launched Threat Intelligence Lookup in February 2024, but we’ve been testing it together with early adopters from our community for several months prior to the public release. This product feels like the next logical step for us, a completely new way to bring value to our users.
In the first iteration we focused on giving you all the data we had at once in a package that is user-friendly both for building searches and for browsing the results.
Some things we had to leave out to make it in time for our planned release window. For example, you can’t yet search across our collection of artifacts by YARA rules. Dmitry, Kirill, and others in our TI Lookup taskforce are already working on shipping this feature — along with more transformative ones that we can’t quite talk about yet.
No matter where we go, we’ll stay true to ANY.RUN value: making what we believe are among the most intuitive security products in the industry.
If you’re an enterprise with five or more members in your security team, and currently building your SOC processes, we invite you to try our new platform. Get in touch with our sales team, and we’ll provide you with access to a 14-day trial.




0 comments